Research
Article
Intonation and duration curve in Persian interrogative sentences
Maryam
Nikravesh1, Farhad Torabinezhad1, Ali Ghorbani1,
Mohammad Reza Keyhani2
1- Department of Speechtherapy,
Faculty of Rehabilitation, Tehran University of Medical Sciences, Iran
2- Department of
Biostatistics, Faculty of Rehabilitation, Tehran University of Medical
Sciences, Iran
Received:
12 April 2011, accepted: 23 October 2011
Abstract
Background and Aim: prosody is a
very important factor in communication and includes such parameters as:
duration, intonation, pitch, stress, rhythm etc. Intonation is the pitch
variation in one sentence. Duration is the time taken to utter a voice. The aim
of the present study was to evaluate some parameters of prosody such as duration
and intonation curve in interrogative sentences among normal Farsi speaking
adults in order to determine the characteristics of this aspect of language
with an emphasis on laboratory testing.
Methods: This study was
performed as a cross-sectional one. The participants included 134 male and
female Farsi speaking individuals aging between 18-30 years. In this study two
interrogative sentences with open and closed answers were used. The voice
samples were analyzed by Dr.speech -real analysis software. Data analysis
incorporated unilateral analysis of variance and an intonation curve was drawn
for each sentence.
Results: The parameter
of duration among men and women was significantly different (p≤0.001).
Duration in open questions was significantly longer than yes/no questions
(p≤0.001). The intonation curve of the two groups were similar.
Conclusion: Men and women
use duration changes, for making difference in prosody. On the whole, duration
among women is longer than men. In open questions, the duration of sentences is
mostly due to the question word. The intonation curve in open
questions has more amplitude. Women show much more changes in basic frequency
for transferring interrogative state in their expressions.
Keywords: prosody,
intonation curve, duration, interrogative sentences, Persian
مقاله پژوهشی
منحنی آهنگ و
دیرش در جملههای پرسشی زبان فارسی
مریم
نیکروش1، فرهاد ترابینژاد1، علی
قربانی1، محمدرضا کیهانی2
1ـ گروه
گفتاردرمانی، دانشكده
توانبخشي، دانشگاه علوم پزشكي تهران، ايران
2ـ گروه آمار
زیستی، دانشکده توانبخشی، دانشگاه علوم پزشکی تهران،
ایران
چکیده
زمینه و هدف: نوای گفتار از مؤلفههای مهم برقراری ارتباط است که شامل: آهنگ،
دیرش، زیروبمی، بلندی، تکیه، وزن و غیره است.
آهنگ عبارت است از تغییراتی که در زیروبمی صدا در
گفتار پیوسته در سطح جمله رخ میدهد. دیرش بهمدت زمان
ادای یک صوت اطلاق میگردد. هدف این پژوهش بررسی مؤلفههایی
از نوا شامل دیرش و منحنی آهنگ در جملات پرسشی بزرگسالان بهنجار
فارسی زبان بود، تا با تکیه بر جنبههای آزمایشگاهی
ویژگیهای این بعد از گفتار مشخص شود.
روش بررسی: پژوهش حاضر از نوع مقطعی بود. آزمودنیها
شامل 134 زن و مرد 18 تا 30 سالۀ بهنجار فارسیزبان بودند. دو
جملۀ پرسشی مورد بررسی قرار گرفت. یک جمله دارای
کلمۀ پرسشی و دیگری بدون کلمۀ پرسشی بود. نمونههای
صوتی با استفاده از برنامۀDr.speech نرمافزار real analysis تجزیه و تحلیل شده و دادهها
با آنالیز واریانس یکطرفه مورد بررسی قرار گرفتند و
منحنی آهنگ جملهًها رسم شد.
یافتهها: دیرش زنان و مردان در جملهها تفاوت معنیداری
داشت(001/0p≤).
دیرش جملۀ پرسشی
با کلمۀ پرسشی بیش از جملۀ پرسشی بدون کلمۀ
پرسشی بود(001/0p≤).
منحنی آهنگ در گروه
زنان و مردان الگوی مشابهی داشت.
نتیجهگیری: زنان و مردان برای ایجاد
تغییر در نوای گفتار از تغییر دیرش استفاده
میکنند. بهطور کلی دیرش در زنان بیش از مردان بود. در
پرسش با کلمۀ پرسشی بخش اعظم دیرش مربوط به کلمۀ
پرسشی است. منحنی آهنگ در پرسش با کلمۀ پرسشی دامنۀ
بیشتری داشت. زنان نسبت به مردان برای انتقال حالت پرسشی
در گفتار تغییرات بیشتری در فرکانس پایه نشان
میدادند.
واژگان کلیدی: نوای گفتار، منحنی آهنگ،
دیرش، جملۀ پرسشی، زبان فارسی
(دریافت مقاله: 23/1/90، پذیرش: 1/8/90)
مقدمه
در
گفتاردرمانی، بررسیهای بالینی صوت اغلب محدود به
اندازهگیری ابعاد مختلف فرکانس شامل میانگین، دامنه،
هیستوگرام و در مواردی نما و میانه است. هر چند این موارد
کاربردهای ارزشمند خود را دارند، ولی اطلاعاتی از چگونگی
این تغییرات در جمله ارائه نمیکنند، این جنبه از صوت
زیرعنوان نوای گفتار (speech
prosody) شناخته میشود. در واقع اطلاعات گفتاری نه تنها از
طریق واحدهای زنجیری مانند واکهها و همخوانها بلکه از
طریق نوای گفتار نیز منتقل میشوند. نوای گفتار
بسیار پیچیده است و چند عامل با هم در شکلگیری این مفهوم نقش دارند.
برخی از مؤلفههای تأثیرگذار در نوای گفتار عبارتند از:
زیروبمی، بلندی، دیرش، و مکث. همچنین مؤلفههایی
چون آهنگ، تکیه و وزن در شکلدهی به نوای گفتار مؤثر هستند. به
کمک نوای گفتار میتوان جنبههای متفاوتی از حالات
گوینده یا (عبارت حالت عاطفی گوینده، حالت عبارت خبری،
پرسشی) را نشان داد و نیز میتوان تأکید، تمایز و
جنبههای دیگری از زبان را منتقل نمود که با دستور زبان و
یا کلمات قابل انتقال نیستند(1). ارزیابی نوا برای
تشخیص و درمان اختلالات گفتار و زبان، تشخیص شرایط عصبشناختی
و یادگیری زبانهای خارجی مهم است(2). تولید
و درک نوای گفتار مؤلفۀ مهمی در تعاملات اجتماعی انسانها
است(3). الگوی آهنگ اغلب بین زبانها متفاوت است و باعث ایجاد
تمایز در زبانها میشود(4). نوای گفتار در مراحل اولیۀ
رشد، در شکلگیری زبان و برقراری ارتباط متقابل کودک و بزرگسال
نقش اساسی ایفا میکند. نوای گفتار محیط
پیرامون نوزاد، بر آهنگ گریۀ نوزاد تأثیرگذار است(5). در
تبادلات ارتباطی، اطلاعات فرازبانی تحت پوشش نوا قرار میگیرند(6). از
خصوصیات نواییـصوتی مرتبط با فرکانس پایه، دیرش
و کیفیت صوت برای درک اطلاعات فرازبانی مانند آهنگ، لحن و
احساسات در گفتار محاوره میتوان استفاده کرد. فرکانس پایه و
دیرش را برای تشخیص اطلاعات فرازبانی مانند تصدیق
کردن، انکار کردن و غیره میتوان بهکاربرد(7). در این پژوهش از
آهنگ به منحنی آهنگ (intonation curve) تعبیر شده است، به این دلیل که هدف عمده در
این پژوهش رسم منحنی از تغییرات آهنگ بهمنظور
بررسی نوا است. دیرش به معنی مدت زمان ادای یک صوت،
در برخی زبانها مانند عربی و انگلیسی یک عنصر
واجی است یعنی تقابل معنایی ایجاد میکند،
اما در فارسی چنین نقشی ندارد و تنها یک عنصر
آوایی است. آهنگ عبارت است از تغییراتی که در
زیروبمی صدا در گفتار پیوسته در سطح جمله رخ میدهد(8). Jun (2005) زبان فارسی، انگلیسی، آلمانی،
هلندی، یونانی، ایتالیایی،
اسپانیایی، پرتغالی و عربی را در یک طبقهبندی
قرار داد. در این زبانها تغییرات زیروبمی
معنی کلمات را تغییر نمیدهد، اما میتواند جملۀ
خبری را به پرسشی تبدیل نماید و یا با تأکید
روی کلمات مختلف عملکرد کاربردشناختی آنها را تحت تأثیر قرار
دهد(9).
حیاتی
(1998) بیان کرد که الگوهای آهنگین زبان فارسی و
انگلیسی بسیار مشابه هستند. در هر دو زبان عبارات خبری و
پرسشی با کلمۀ پرسشی، افتان و در پرسشهایی با پاسخ
بله/خیر، خیزان هستند(10).
براساس
ماهوتیان (1997) و سادات تهرانی (2003) در جملههای پرسشی
با کلمۀ پرسشی، در پایان جمله حالت افتادن دیده میشود،
اما در پرسشهایی با پاسخ بله/خیر، نتایج متفاوت
 است
و در پایان جمله حالت خیزان دیده میشود(11و12).
است
و در پایان جمله حالت خیزان دیده میشود(11و12).
Clopper و همکاران (2011) در پژوهشی که در زبان انگلیسی
امریکایی انجام دادند اظهار داشتند که ویژگیهای
جنسیتی بر نوای گفتار اثرگذار است(13).
دیرش
واکهها و تفاوت در فرکانس پایه باعث ایجاد تنوع در منحنی آهنگ
شده و بین جملههای خبری و پرسشی تفاوت ایجاد
میکند(14).
سابقۀ
پژوهشی مشابه پژوهش حاضر از نظر روش کار در داخل کشور وجود ندارد. مطالعات و
پژوهشهای قبلی مؤلفههای نوای گفتار را بهصورت
کیفی مورد بررسی قرار دادهاند. پژوهش حاضر اولین
کاری است که با هدف تعیین منحنی آهنگ و دیرش در جملههای
پرسشی
(یک
جملۀ پرسشی با کلمۀ پرسشی و یک جملۀ بدون کلمۀ
پرسشی) در زبان فارسی انجام شده است. آگاهی از این جنبۀ
نوای گفتار علاوه بر اینکه در تبیین نقش آن در زبانشناسی
به کار خواهد آمد، زمینه را برای توسعۀ مطالعات
بالینی نوای گفتار فراهم خواهد کرد.
روش بررسی
این
مطالعه از نوع مقطعی و غیرمداخلهای بوده است. جمعیت مورد
بررسی 67 زن و 67 مرد 18 تا 30 سالۀ عادی فارسی زبان
بودند.
برای جلوگیری از تأثیرگذاری لهجه بر مؤلفههای
نوای گفتار، انتخاب گویشورانی که زبان اول آنها فارسی
باشد مد نظر بود. نمونهگیری بهصورت غیراحتمالی (نمونهگیری
ساده) بود. نمونهها از میان دانشجویان دانشکدۀ توانبخشی
دانشگاه علوم پزشکی تهران انتخاب شدند. در ابتدا هر کدام از آزمودنیها
رضایتنامۀ کتبی را مطالعه و امضا نمودند، سپس زبان
مادری، سن و عدم ابتلا به سرماخوردگی در زمان نمونهگیری
با استفاده از پرسشنامهای مورد سؤال قرار گرفت. دو گفتاردرمانگر سلامت
آزمودنیها را در زمینۀ گفتار و زبان تأیید کردند.
برای
ضبط نمونۀ صوتی آزمودنیها با مطالعۀ پیشینۀ
پژوهشهایی که در زمینه آهنگ زبان فارسی انجام شده بود و
با مشورت با صاحبنظران گفتاردرمانگر (آسیبشناس گفتار و زبان) و زبانشناس
جملههایی تهیه شدند که محاورهای باشند، در گفتار روزمره
فرکانس وقوع نسبتاً بالایی داشته باشند، مربوط به گروه، طبقه و
عقیدۀ خاصی نباشند و به سطح تحصیلات نیز
بستگی نداشته باشند. جملههای کوتاه (کمتر از پنج کلمه) انتخاب شدند
تا بررسی آنها دشوار  نباشد و نیز برای
حفظ پیوستگی نمودار فرکانس پایه و حذف یا کاهش گسیختگی،
درصد وقوع صداهای واکدار نسبت به صداهای بیواک در جملهها
زیاد باشد.
نباشد و نیز برای
حفظ پیوستگی نمودار فرکانس پایه و حذف یا کاهش گسیختگی،
درصد وقوع صداهای واکدار نسبت به صداهای بیواک در جملهها
زیاد باشد.
با
توجه به معیارهای فوق 40 جملۀ پرسشی انتخاب شد، و
روایی محتوایی هشت جمله با نظر 13 صاحبنظر تأیید
شد. سپس جملهها توسط چهار گوینده (دو زن و دو مرد) خوانده شد و صدای
آنها با برنامه real
analysis در نرمافزار Dr. Speech
تجزیه و تحلیل شد. از آن میان، دو جمله انتخاب شد که
منحنی فرکانس پایۀ آنها پیوستگی بیشتری
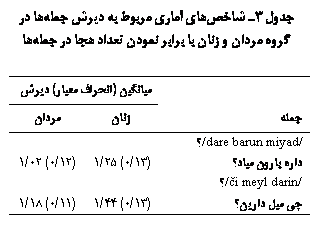
داشت. جملهها عبارت بودند از: «داره بارون میاد؟»، «چی میل دارین؟» (جدول 1).
نمونهگیری
گفتار آزمودنیها در آزمایشگاه گفتار و زبان دانشکده توانبخشی
دانشگاه علوم پزشکی تهران انجام شد. برای نمونهگیری
حداقل دو ساعت از بیداری فرد گذشته بود تا فرد به صدای ثابت
روزمرۀ خود رسیده باشد. آزمودنیها در حین نمونهگیری
در وضعیت نشسته و کاملاَ صاف قرار میگرفتند و فاصلۀ
آزمودنی تا میکروفن 20 تا 25 سانتیمتر بود. سر و صدای

زمینهای
محیط حداکثر 35 دسیبل و تقویت صدای آزمودنیها
برای ضبط صدا 20 دسیبل بود. نمونههای صوتی با فرمت bit mono 16، Hz 44100 ضبط شدند. قبل از نمونهگیری، از آزمودنیها
خواسته میشد جملهها را با بلندی عادی و حالت
طبیعی و بدون تأکید روی واژهای خاص و یا به
قصد القای مفهومی خاص (بینشان) بیان کنند. در آغاز ضبط
نمونۀ صوتی، دستکم یک ثانیه صدای محیط
(سکوت) ضبط میشد تا از نبود نویز در محیط اطمینان حاصل
شود. بعد از اتمام ضبط نمونههای صوتی، دیرش جملههای مورد
مطالعه با دقت دهم ثانیه از ابتدا تا انتهای جمله اندازهگیری
شد. برای تعیین دقیق دیرش جمله، در ابتدا با توجه
به موج صوتی ارائه شده توسط نرمافزار real analysis ابتدا و انتهای موج صوتی بهعنوان ابتدا و
انتهای جمله در نظر گرفته شد. سپس، اسپکتوگرام مد نظر قرار گرفت و ابتدا و
انتهای جمله دقیقتر مشخص شد. گوش دادن به نمونۀ صوتی،
آخرین مرحلۀ ویرایش بود. به این صورت، ترتیب
دیرش دقیق هر جمله محاسبه شد. برای مقایسۀ
دیرش دو جمله باید طول جملهها از نظر تعداد هجا یکسان در نظر
گرفته شود. برای این منظور با برقرار نمودن نسبتی میان
دیرش و تعداد هجا در جملهها طول دو جمله از نظر تعداد هجا یکسان در
نظر گرفته شد.
 در رسم منحنی
آهنگ، روی نمودار فرکانس پایۀ هر یک از نمونهها مطابق
شکل 1 نقاطی علامتگذاری شد. چون دیرش جملهها در نمونههای
صوتی متفاوت بود، یک معیار واحد برای رسم منحنی آهنگ مورد
نیاز بود. برای حل این موضوع در هر نمونۀ صوت، زمان در هر
نقطه (نقاط تعیین شده در شکل 1) به زمان کل همان نمونۀ
صوتی تقسیم شد و با این کار دیرش جمله در همۀ نمونهها
یک واحد در نظر گرفته شد (برای مثال در مورد نمونۀ صوتی
که دیرش آن 2/1 ثانیه بود، زمان هر نقطۀ تعیین شده
بر 2/1 تقسیم شد). سپس، در نمونههای صوتی میانگین
اعداد مربوط به فرکانس و زمان در هر نقطه بهصورت جداگانه محاسبه گردید و
براساس میانگینها منحنی آهنگ جملهها رسم شد.
در رسم منحنی
آهنگ، روی نمودار فرکانس پایۀ هر یک از نمونهها مطابق
شکل 1 نقاطی علامتگذاری شد. چون دیرش جملهها در نمونههای
صوتی متفاوت بود، یک معیار واحد برای رسم منحنی آهنگ مورد
نیاز بود. برای حل این موضوع در هر نمونۀ صوت، زمان در هر
نقطه (نقاط تعیین شده در شکل 1) به زمان کل همان نمونۀ
صوتی تقسیم شد و با این کار دیرش جمله در همۀ نمونهها
یک واحد در نظر گرفته شد (برای مثال در مورد نمونۀ صوتی
که دیرش آن 2/1 ثانیه بود، زمان هر نقطۀ تعیین شده
بر 2/1 تقسیم شد). سپس، در نمونههای صوتی میانگین
اعداد مربوط به فرکانس و زمان در هر نقطه بهصورت جداگانه محاسبه گردید و
براساس میانگینها منحنی آهنگ جملهها رسم شد.
بهمنظور
تحلیل اطلاعات مربوط به دیرش از آزمون تحلیل واریانس
یکطرفه استفاده شد. تمامی اطلاعات با نرمافزار SPSS
نسخه 17 مورد تحلیل قرار گرفت. در مورد منحنی آهنگ، براساس
تغییرات فرکانس پایه، الگوی کلی برای هر
یک از جملهها در نرمافزار excel
2007 رسم و نمودارها تحلیل شد.
یافتهها
در
صورت برابر در نظر گرفتن طول جملهها از نظر تعداد هجا، دیرش جملۀ /či meyl darin/؟ بیشتر از جملۀ
dare barun
miyad/؟/ است. نتیجۀ آزمون آنالیز واریانس یکطرفه
نشان داد که بین میانگین دیرش جملههای مورد
بررسی تفاوت معنیداری وجود دارد(001/0p≤).
با
این فرضیه که دیرش تولید جملهها در دو جنس متفاوت است، آزمون آنالیز
واریانس یکطرفه انجام شد. نتیجۀ آزمون آنالیز
واریانس یکطرفه نشان داد که در میانگین دیرش جملههای
مورد مطالعه در دو جنس تفاوت معنیداری وجود دارد(001/0p≤). دادههای حاصل از این پژوهش نشان داد که دیرش
تولید هر دو جمله در زنان بیش از مردان است. نتایج حاصل از
بررسی دیرش در زنان و مردان در جدولهای 2 و 3 آورده شده است.
 از نظر بررسی آهنگ، جملۀ dare barun miyad/?/: در هر دو گروه از زمان صفر شروع شده است (نمودار 1) و در هر دو نمودار
دو قلۀ فرکانس دیده میشود که اولی کوتاهتر از
دومی است، و در پایان جمله حالت خیزان دیده میشود.
در مجموع منحنی آهنگ جملۀ dare barun miyad/?/ در هر دو جنس مشابه
است.
از نظر بررسی آهنگ، جملۀ dare barun miyad/?/: در هر دو گروه از زمان صفر شروع شده است (نمودار 1) و در هر دو نمودار
دو قلۀ فرکانس دیده میشود که اولی کوتاهتر از
دومی است، و در پایان جمله حالت خیزان دیده میشود.
در مجموع منحنی آهنگ جملۀ dare barun miyad/?/ در هر دو جنس مشابه
است.
جملۀ
/či meyl darin/?: از نقطۀ صفر
شروع نشده است (نمودار 2) زیرا آوای اول جمله واج /č/ بیواک است و
در منحنی آهنگ ثبت نمیشود. به همین دلیل، نمودار از نقطۀ
2/0 ثانیه پس از آغاز بیان جمله شروع شده است. در منحنی آهنگ
این جمله یک قلۀ فرکانس مشاهده میشود که مربوط به
واژۀ پرسشی آغاز جمله (/ič/) است و در پایان جمله حالت افتان مشاهده
میشود که پایینتر از سطح فرکانس اول جمله است.
بحث
مقایسۀ
دیرش در زنان و مردان نشان میدهد که دیرش تولید هر دو
جملۀ dare
barun miyad/?/ و /či
meyl darin/? در زنان بیش از مردان است. این
تفاوت دیرش در هر دو جمله تقریباَ به یک میزان بود و با
توجه به میانگینها مقدار این تفاوت بهطور متوسط 20 درصد است.
این تفاوت دیرش در میان زنان و مردان ممکن است به این
دلیل باشد که زنان واکهها را با کشش بیشتری تولید
میکنند.
با
یکسان در نظر گرفتن طول جملهها از نظر هجایی

دیرش در پرسش با
کلمۀ پرسشی نسبت به پرسش با پاسخ بله/خیر در هر دو جنس بیشتر
است. وجود کلمۀ پرسشی میتواند باعث افزایش دیرش در
این نوع جمله شود. در واقع بخش اعظم دیرش مربوط به کلمۀ
پرسشی است که نتیجۀ تأکید به کار رفته روی کلمۀ
پرسشی است.
منحنی
آهنگ جملۀ پرسشی با پاسخ بله/خیر (؟dare barun miyad//) حالت خیزان در فرکانس انتهای جمله دارد که از فرکانس شروع
جمله بالاتر است، و برخاستگی نمودار فرکانس در این جمله نشاندهندۀ
آهنگ خیزان پرسشی است. اختلاف فرکانس ابتدا و انتهای جمله در
زنان حدود دو برابر اختلاف فرکانس ابتدا و انتهای جمله در مردان است. از
این یافته میتوان نتیجه گرفت که حالت خیزان
انتهای جمله در زنان بیشتر است و زنان از تغییرات فرکانس
برای انتقال حالت پرسشی جمله بیشتر از مردان استفاده میکنند.
در
جملۀ پرسشی با پاسخ بله/خیر حالت خیزان در انتهای
جمله مشاهده میشود. این یافته با یافتههای
مطالعات حیاتی، ماهوتیان، سادات تهرانی (12-10) همخوانی
دارد، البته در پژوهشهای قبلی گروه زنان و مردان با هم مقایسه
نشدهاند.
در
پرسش با کلمۀ پرسشی (؟či meyl darin//) منحنی مربوط یک قلۀ فرکانس دارد که مربوط به
زیروبمی کلمۀ پرسشی (/či/) است. در این
جمله نیز در گروه زنان اختلاف بین فرکانس ابتدا و انتهای جمله
بیش از مردان است. زنان در این نوع جمله نیز از
تغییرات فرکانس بیش از مردان استفاده میکنند.
در
مورد جملات پرسشی با کلمۀ پرسشی انتهای جمله حالت افتان
دارد و قلۀ فرکانس روی کلمۀ پرسشی قرار دارد. این
یافته با یافتههای مطالعات حیاتی، ماهوتیان،
سادات تهرانی (12-10) همخوانی دارد.
الگوی
منحنی آهنگ زنان و مردان در هر دو جمله مشابه است با این تفاوت که
زنان و مردان هر یک در محدودۀ فرکانس مربوط به جنس خود این الگو
را ایجاد میکنند.
نتیجهگیری
زنان
و مردان برای ایجاد تغییرات نوای گفتار از
تغییر دیرش با یک الگوی یکسان استفاده
میکنند، ولی با این تفاوت که دیرش در زنان بهطور
کلی بیش از مردان است. وجود کلمۀ پرسشی در جمله باعث
افزایش دیرش نسبت به پرسش بدون کلمۀ پرسشی میشود. فرکانس
انتهایی جمله در پرسش با پاسخ بله/خیر (؟dare barun miyad//) خیزان است. در این جمله برای ایجاد حالت
پرسش، زنان نسبت به مردان تغییرات بیشتری در فرکانس
انتهایی جمله ایجاد میکنند. فرکانس انتهایی جمله
در پرسش با کلمۀ پرسشی (؟či meyl darin//) افتان است. در این جمله نیز میتوان گفت که زنان
نسبت به مردان برای انتقال حالت پرسشی فرکانس پایۀ صوت را
بیشتر تغییر میدهند. در هر دو جنس منحنی آهنگ در
پرسش با کلمۀ پرسشی دامنۀ بیشتری دارد.
سپاسگزاری
نویسندگان
مقاله از استاد گرانقدر جناب آقای دکتر یحیی مدرسی،
که در انجام این پژوهش یاریگر آنها بودند، سپاسگزاری
مینمایند.
REFERENCES
1.
Xu Y. Speech prosody: a
methodological review. Joss. 2011;1(1):85-115.
2.
van
Santen JP, Prud'hommeaux ET, Black LM. Automated assessment of prosody
production. Speech Commun. 2009;51(11):1082-97.
3.
Aziz-Zadeh
L, Sheng T, Gheytanchi A. Common premotor regions for the perception and
production of prosody and correlations with empathy and prosodic ability. PLoS One. 2010;5(1):e8759.
4.
Wennerstrom A.
The music of everyday speech: prosody and discourse analysis. 1st ed.
New York: OxFord University Press; 2001.
5.
Mampe
B, Friederici AD, Christophe A, Wermke K. Newborns' cry melody is shaped by
their native language. Curr Biol. 2009;19(23):1994-7.
6.
Greenberg
Y, Shibuya N, Tsuzaki M, Kato H, Sagisaka Y. Analysis
on paralinguistic prosody control in perceptual impression space using multiple
dimensional scaling. Speech Commun. 2009;51(7):585-93.
7.
Ishi
CT, Ishiguro H, Hagita N. Automatic extraction of paralinguistic information
using prosodic features related to F0, duration and voice quality.Speech Commun. 2008;50(6):531-43.
8.
Lickley
RJ, Schepman A, Ladd
DR. Alignment of "phrase accent" lows in dutch falling rising
questions: theoretical and methodological implications. Lang Speech. 2005;48(Pt
2):157-83.
9.
Jun
S. Prosodic typology. In: Jun S editor. Prosodic typology: the phonology of
intonation and phrasing. Oxford: Oxford University Press; 2005. p. 430-58.
10.
Hayati
AM. A contrastive analysis of English and Persian intonation. In: Fisiask J, editor.
Papers and studies in contrastive linguistics Volume 34. Poznan: Adam
Mickiewicz University; 1998. p. :53-72.
11.
Mahootian
S. Persian (descriptive grammars). 1st ed. London: Routledge; 1997.
12.
Sadat-tehrani
N. The alignment of L+H* pitch accents in Persian intonation. J Int Phon Assoc.
2009;39(2):205-30.
13.
Clopper
CG, Smiljanic R. Effects of gender and regional dialect on prosodic patterns in
American English. J Phon. 2011;39(2):237-45.
14.
Whitehead
RL, Schiavetti N, Metz DE, Gallant D, Whitehead BH.
Sentence intonation and syllable stress in speech produced during simultaneous
communication. J Commun Disord. 2000;33(5): 429-40; quiz 440-1.